我们使用一些Slice和乘法器,对这些硬件模块中的两个进行例化。两个内核都要求4到5个周期的延迟,以匹配我们设计的时序要求。延迟在此不是什么问题,我们将在下面的步骤中进行讨论。
我们将最终的IP以MicroBlaze的快速单工链路 (FSL) IP 的形式进行实现。对时序的第一次估算结果表明:
• 将数据从MicroBlaze传输到FSL总线需用一个时钟周期
• 将数据从FSL总线传输至FSL IP(当正弦计算的自变量从FSL总线读出时,将立即从BRAM读取数据,因而无需时钟周期)需用一个时钟周期
• 完成MUL运算 (cos(x)*sin(d)) 需用四个时钟周期
• 将方程的结果存储到寄存器中需用一个时钟周期
• 完成ADD运算需用四个时钟周期
• 将数据发送回FSL总线需用一个时钟周期
• MicroBlaze从FSL IP读取数据需用一个时钟周期。
请注意,在没有使用任何额外流水线(我们将在下一步骤中讨论这一点)的情况下,自变量数据在整个过程中必须保持稳定。这就意味着MicroBlaze仅能请求一次正弦计算,且必须读取该值,然后至少要等上13个时钟周期,才能请求下一次计算。
因此,我们估计进行该实现需要13个时钟周期。当然,要处理软件上的函数调用以及某些其他运算,还需要更多的时钟周期。
我们简单地把一些标准时钟组合在一起,不到一天就实现了该IP,随即在硬件中对该算法进行测量。整个算法(软硬件混合)耗用了360个时钟周期(包括所有的函数调用)。虽然这已是显著的进步,但是仍不足以充分满足客户的需求。
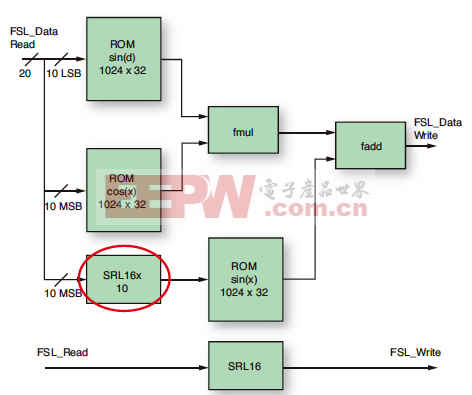
在我们的加速器IP处理所有数据之前,我们使用一个SRL16来延迟信号的写入。
虽然该算法现在可与我们的MicroBlaze并行运行,但它每次只能计算一个值。
步骤六:添加流水线和适配客户代码
设计到了这一步,我们就可以开始向我们的内核添加流水线。浮点ADD和浮点MUL的CORE Generator模块已采用流水线实现,因而我们在此无需再做什么。第一个版本的算法要求自变量保持恒定,直至计算完成。在开始新计算之前(自变量数据到达FSL IP内部),立刻读取两个BRAM并执行浮点MUL。运算的结果在数个时钟周期后生效。
我们的 sin(xi) 的自变量 xi 是一个20位宽的整数,它分为 x 和 d 两个部分。因此,我们必须对自变量 xi的MSB部分 x 进行几个时钟周期的延迟,以读取 BRAM 的内容,存储自变量xi,并将其与MUL运算的结果相匹配。
我们为我们的10位宽数值使用了少量SRL16元件(总共 10 个),共占用了10个LUT(但由于Spartan-6具有LUT组合功能,如果采用该器件较宽的LUT6结构,则仅需 5 个 LUT 即可)。
最后的工作量相当小。在图4中已对增加的SRL16x10位用红圈进行了标注。
然后我们使用EDK向导来修改我们的FSL总线FIFO,以便存储多个值(我们确定能够存储8个值就足以达到我们的目的,但可根据需要轻松增加更多)。
这就意味着我们的客户甚至在请求第一个结果之前即能获得多达8个值。这足以满足我们客户当前的需求,但如果想请求更多正弦值的话,则可以轻松将FIFO缓冲参数扩展为较大的值。
我们在与客户讨论这种新的方案时,发现可将正弦计算进一步划分为两个部分:
1. 请求正弦计算(fslput 运算)
2. 请求正弦计算的结果(fslget运算)
由于我们在运算中有一个固定时延,所以如果这两个运算依次衔接、紧密地按顺序执行,那么MicroBlaze将停顿,并等待FSL IP完成对请求的处理。如果能够将这两组运算分开(这在客户的算法中是可以的),那么我们即可进一步提
升运算的总体速度。通过增加流水线, 在MicroBlaze上执行的最终代码如下:
putfsl(arg1,fsl1_id);
putfsl(arg2,fsl1_id);
putfsl(arg3,fsl1_id);
putfsl(arg4,fsl1_id);
putfsl(arg5,fsl1_id);
putfsl(arg6,fsl1_id);
putfsl(arg7,fsl1_id);
putfsl(arg8,fsl1_id);
...
getfsl(result1,fsl1_id);
getfsl(result2,fsl1_id);
getfsl(result3,fsl1_id);
getfsl(result4,fsl1_id);
getfsl(result5,fsl1_id);
getfsl(result6,fsl1_id);
getfsl(result7,fsl1_id);
getfsl(result8,fsl1_id);
这给我们带来了显著的优势。内核不仅可完全实现流水线功能,而且还能够将正弦计算的两个调用分开。IP核的时延依然存在,但不再明显。MicroBlaze也不再发生停顿和等待未完成的IP计算的情况,从而提高了整体性能。
客户同意对代码进行相应调整,这对客户来说只是小量工作。通过使用C语言的宏命令取代函数调用,我们就能够把所有要求的调用插入代码库中。