如果我们的 FAST 搜索引擎能够与客户数据流的匹配,则会执行指定的任务,如果不能,就执行默认的规则(丢弃或发送至 NPU)。我们允许的基本任务包括:丢弃包、将包直接转发至网络端口、将包转发给异常包处理 NPU 或复制包并依据独立规则转发包。我们的扩展任务包括包塌缩 (Packet collapse)(删除包的一部分)、包扩展/写入(在包中插入一系列字节)、包覆盖 (packet overwrite)(修改一系列字节)及其组合。以包覆盖规则为例,可以是修改MAC 源地址或目的地地址、修改 VLAN 的内或外部标记 (tag),或更改第 4 层报头标记。插入/删除的例子可以是简单到删除现有的 EtherType、插入 MPLS 标签或者 VLAN Q-in-Q 标记,也可以是复杂到需要先插入一个作为 GRE 交付报头的 IP 报头,接着紧随一个 GRE 报头(通用路由协议封装 (GRE) 是一种隧道协议,具体参阅因特网 RFC 1702 号文件)。
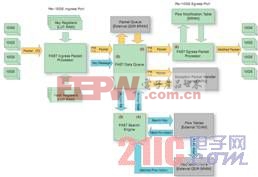
图 1 – 流加速子系统中的数据流

图 2 – 针对 Type II 以太网 TCP/IP 包的 5 元组密钥提取
FAST 包处理器
FAST 入口包处理器可对所有包进行解码,以确定第 2 层、3 层以及 4 层的内容(若存在)。在完成以太网第 2 层的初步解码之后,可对包进行更进一步的 2 层处理。随后我们继续进行第 3 层,处理 IPv4 或 IPv6 包。假定我们发现这种第 3 层类型的其中之一存在,我们即继续进行第 4 层处理。
在对包进行解码的同时,我们的密钥抽取单元也在定位并存储密钥字段,以生成可供我们 FAST 搜索引擎在日后用于数据流查找的搜索密钥。图 2 是 Type II 以太网 (Ethernet Type II)的 TCP/IP 包格式和待抽取的标准 5 元组密钥,此外还显示了从本例中抽取的结果密钥。
我们还可同时对入口处理器与出口处理器的各类包执行 IP、TCP、UDP 以及 ICMP 校验和计算。两个 Virtex-5 FPGA DSP48E slice 可提供校验和计算以及验证所需的加法器。我们的第一个 DSP 可在 32 位的边界内对数据流进行汇总,而第二个 DSP 则负责在相关层的计算结束时将所得总数折叠成 16 位的校验和。然后我们进行校验和的计算;对于重计算,我们可将传输进入的数据流的校验和字节位置清空,使用存储缓冲器将校验和结果的倒数重新插回。可将第 4 层校验和要求的伪报头字节多路复用到传输进入的数据流中,以用于最终计算。
每个输出端口的 FAST 出口包处理器都可根据规则表(规则存储在内部 BRAM 中)进行包修改和第 3 层至 4 层校验和的重新计算及插入。该 FEPP 超越了传统的包修改“固定功能”方案,从而能够按照指定的修改规则编号对包进行覆盖、插入、删除或者截断操作等修改。我们的数据流修改规则支持可代表操作类型的操作码规范,以 OpLoc 代表启始位置、OpOffset 代表偏移、Insert Size 代表插入的数据大小、Delete Size 代表删除的数据大小,以及是否执行第 3 层和第 4 层校验和计算和插入以及是否进行修改规则链化。
我们的新一代实施方案不仅能够显著提升性能、进一步加强高速缓冲的能力,同时还能添加新功能。通过把我们的 FAST 芯片组升级到单个的赛灵思 Virtex-6 FPGA,我们不仅能够将新一代 FAST 的功能、接口和性能提升到一个前所未有的水平,同时还能缩小板级空间并降低功耗要求,从而实现单芯片深度包处理协处理器单元。
我们能够使用包覆盖特性来简单地对诸如 MAC 目的地地址、MAC 源地址、VLAN 标记甚或是单个 TCP 标志等现有字段进行修改。