视频流和下载通常会耗掉消费者绝大部分互联网流量,同时也是云计算技术发展的主要推动力。对视频流和下载需求的持续增长,正在驱动视频处理应用迈出专业系统领域,步入数据中心。这一应用模式的转变需要具备快速扩展能力的计算节点来满足视频内容制作和分发的各个不同高计算强度阶段的需求,如转码需求和水印需求。
我们近期使用赛灵思SDAccel™开发环境来编译和优化专为FPGA加速卡采用OpenCLTM编写的视频水印应用。视频内容提供商使用水印起到广告和内容保护的作用。我们的目的是设计一种能处理运行在Alpha Data ADM-PCIE-7V3卡上,吞吐量为30fps,分辨率为1080p的高清(HD)视频的水印应用。
SDAccel开发环境能让设计人员先用OpenCL编写应用,然后在无需了解底层FPGA实现工具的情况下把应用编译到FPGA中。可以以这种视频水印应用为例来介绍SDAccel中的主要优化技巧。
带标识插入功能的视频水印
该视频水印算法的主要功能是在视频流的特定位置覆盖一个标识。用于水印的标识可以是活动的,也可以是静止的。活动标识一般采用简短的重复性视频片段来实现,静止标识则采用静止图像。
广播企业宣传自己视频流最常用的方法是把企业标识用作静止水印,因此成为我们实例设计的目标。该应用根据下列等式,以逐像素粒度插入静止标识。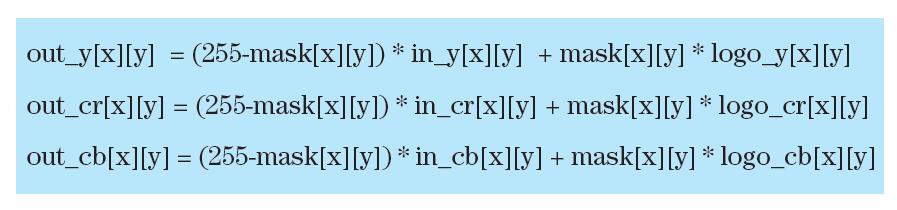
输入和输出帧为二维阵列,像素使用YCbCr色域表达。在该色域中,每个像素用三个分量表达。Y表示亮度分量,Cb表示色度蓝色色差分量,Cr表示色度红色色差分量。每个分量都用一个8位值表达,因为每个像素为24位。
该标识是一个包含待插入内容的二维图像。掩膜也是一个图像,但只包含标识的轮廓图。掩膜的像素可以是白色或黑色。掩膜的白色像素表示标识的插入位置,黑色像素则表示原始像素未被触及的地方。图1所示的,就是这种视频水印算法的运算方式实例。
图1 - 工作中的视频水印算法
目标系统和初始实现方案
我们运行该应用的系统如图2所示。该系统由Alpha Data ADMPCIE-7V3卡组成,该卡通过PCIe®链路与x86处理器通信。在该系统中,主机处理器从磁盘提取输入视频流,将其传输到设备全局内存中。设备全局内存位于FPGA卡上,可供FPGA直接访问。除把视频帧存放到设备全局内存中外,标识和掩膜也从主机传输到FPGA加速器卡上并存入片上内存中,以充分利用BRAM内存的低时延优势。因为本应用使用的是一个静止标识,只需在片上内存中存储静止图像和布局位置数据。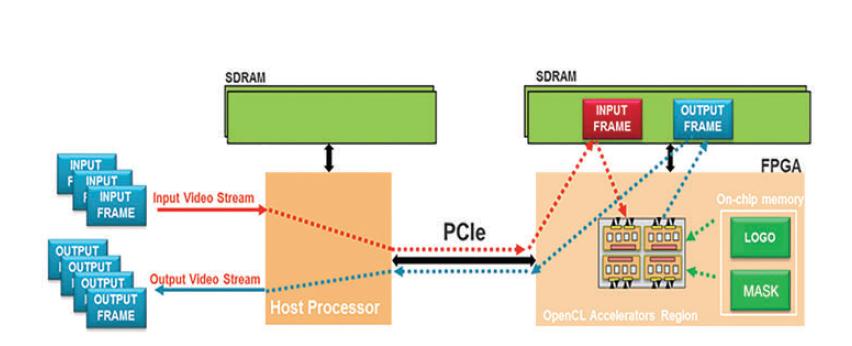
图2 - 视频水印应用系统总览图
创建数据后,主机处理器会给FPGA架构中的水印内核发送一个启动信号。该信号触发内核完成三件工作:开始从设备全局内存获取输入视频帧;在掩膜定义的位置插入标识;将处理过的帧传输回设备全局处理器,等待处理器调用。
视频流中每帧的数据传输与计算的协调工作使用图3所示的代码完成。
图3 - 用于协调每帧数据传输和计算的代码
该代码运行在主机处理器上,负责发送视频帧到FPGA加速器卡,启动加速器,然后从FPGA加速器卡取回处理后的帧。
FPGA水印算法的首个实现方案如图4所示。这是一个功能正确的应用实现方案,但没有进行任何性能优化或为充分利用FPGA架构的功能进行考虑。因此该代码在SDAccel中编译完成后,在Alpha Data卡上运行得到的最大吞吐量仅为0.5fps。
从图4的代码中可以看到,这种水印算法不是一种高计算强度的设计。大多数时间花在访问内存,读取和写入视频帧上。因此我们在优化实例设计时,把重点放在优化内存带宽上。
图4 - 水印内核的初始实现方案
使用矢量化优化内存访问
与其他软件可编程架构相比,FPGA架构的优势之一在于灵活性强,能配置连接内存的总线。SDAccel能根据具体的应用内核创建用于连接内存的定制化数据路径和架构。通过修改代码,一次可以处理多个像素,从而能够从内核中调用更高的内存带宽。这个过程称之为矢量化。
矢量化的程度是否合适,取决于具体应用和所使用的FPGA加速器卡。以Alpha Data卡为例,设备全局内存接口宽度为512位,这与SDAccel为内核提供的最大AXI互联宽度一致。鉴于最大带宽为512位,该应用调整为每次处理20个像素(24位/像素×20像素=504位)。SDAccel完全支持矢量数据类型。因此就本应用而言,代码的矢量化非常简单,就是把所有阵列的数据类型修改为char20(如图5所示),这样吞吐量就能达到12fps。
图5 - 矢量化后的内核代码
使用突发模式优化内存访问
虽然矢量化能显著改善应用性能,但仍不足以实现30fps的吞吐量目标。该应用仍然受内存局限,因为内核每次只能向内存传输20个像素。为减轻内存限制对应用造成的影响,我们不得不修改内核代码,以生成到内存的突发读取/写入操作,从而实现大于20个像素的数据集。修改后的内核代码见图6。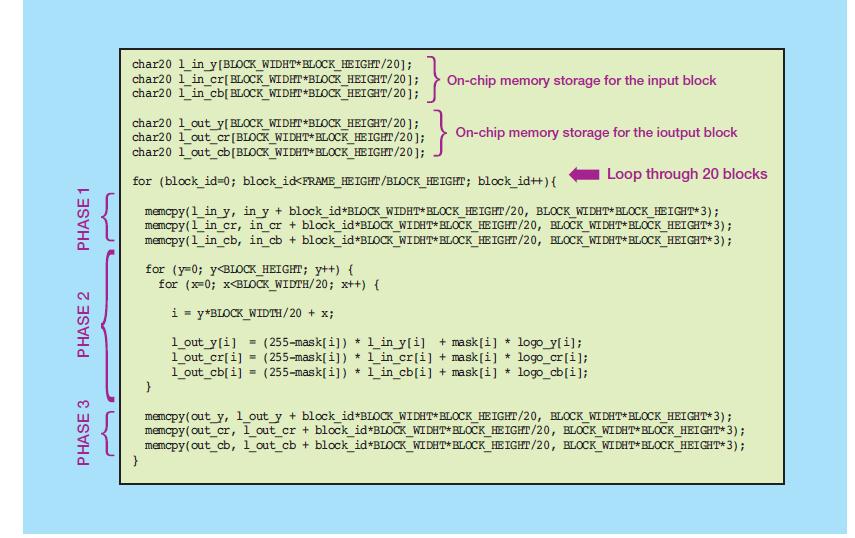
图6 - 针对突发数据传输优化的内核代码
代码内核首先修改的是在内核中定义片上存储,以便每次存储像素块。片上内存用内核代码中声明的阵列来定义。为启动到内存的突发事务处理,该代码实例化memcpy命令,以将数据块从DDR移到内核内的BRAM存储系统中。根据片上内存资源的大小和待处理数据的量,一个视频帧可分割成20个1920×54像素块(如图7所示)。
图7 - 把视频帧分区成数据块
当memcry命令把数据块放置到内核阵列中,该算法就会在数据块上执行水印算法,然后把结果放回内核阵列。数据块处理的结果随后使用memcry命令传送回DDR内存。反复执行这个操作20次,直至给定帧中所有的数据块处理完毕。通过修改内核代码,系统性能达到了38fps,超过了既定的30fps目标。
应用前景广泛
使用SDAccel开发本文介绍的这类应用时所进行的必要优化属于软件优化。因此这些优化工作与从其他处理架构中(如GPU)获取性能所开展的优化类似。使用SDAccel后,让PCIe链路工作、驱动程序、IP布局和互联等细节都不是问题,使我们就像设计人员一样只需集中精力开发目标应用。
我们在水印应用中所做的优化适用于使用SDAccel编译过的所有应用。事实上视频水印应用就是一个很棒的技巧讲解案例,详细介绍了赛灵思SDAccel中推出的优化方法。