作者:Steve Leibson, 赛灵思战略营销与业务规划总监
Adam Taylor's博客系列讲解在基于ARM的Zynq SoC芯片可编程逻辑上实现定点数学函数计算。
我们已经在MicroZed 系列的前期博客中学习了在PL(可编程逻辑)内实现定点运算,现在我们来分析系统内如何执行这些函数,将会发现令人惊讶的结果。
在编写代码前,需要确定我们在特定实例中用到的比例因子(小数点位置)。在这个示例中,输入信号将在0至10范围内,所以我们可以在16位的输入向量内封装4个小数位和12个分数位。
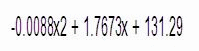
执行上述等式,其中有三个常量 A, B和C:
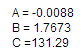
我们需要在计算中缩放这些常量。在FPGA这样做的好处在于,我们可以分别扩展每个常数以优化性能,如表所示:
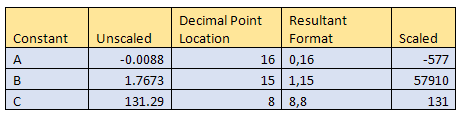
执行上述公式后,我们需要考虑合成向量的扩展,如下图的Ax2 and Bx:
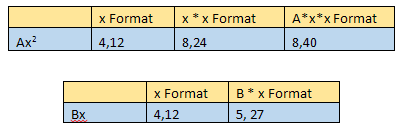
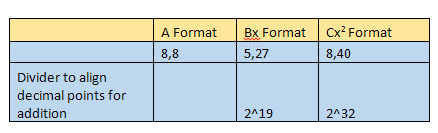
要执行最后加上常量C,我们需要对齐小数位。因此,我们需要将Ax2 和Bx的结果值除以2的乘方,对齐常量C的小数位。结果值的格式为8,8。
完成上述计算后,我们开始在前期博客中创建的Vivado外设中执行设计。第一步是打开Vivado内的框图,右键单击外设,然后选择“Edit in IP Packager”。当IP Packager在顶层文件中打开后,我们可以很容易地执行简单进程,可在数个时钟周期数完成计算。(这个实例中是5个时钟周期,您也可进行进一步优化。)

现在我们可在Vivado内重新封装和重要创建项目(记得更新版本号),然后将更新的硬件导出至SDK。
在SDK内我们可以使用此前使用的相同方法,唯一不同的是以前使用的是浮点系统,现在使用的是定点系统:
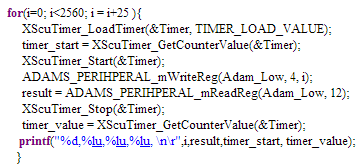
在MicroZed板创建上述代码并运行后,通过通过串行链路输出以下结果:33610除以2 ^ 8结果等于131.289,这个结果值是正确的, (参见Zynq PS/PL, 第5篇: Adam Taylor’s MicroZed 系列25)。

计算结果相同,但最大的区别是计算时间。虽然由于外设执行实际计算只需要5个时钟周期,但生成这个结果值消耗140个时钟周期或42ns,而在使用ARM Cortex-A9处理器在 Zynq SoC PS消耗了25个时钟周期。
为什么会产生差异?难道可编程逻运行速度不够快?
这就需要在外设I / O开销的中所学到的技巧。使用PL,我们必须考虑基于AXI总线和AXI总线频率的总线延时,在这个应用程序中是142.8MHz (所要求的是150兆)。AXI总线开销导致计算时间长于预期。当然所有努力并非徒劳,我们只是执行错误。由于I / O开销的原因,不应使用这种方式卸载Zynq SoC PL任务。
如果我们要采取更加合理的方法,我们会使用DMA发送至外设提出计算要求,正如我在博客系列对有关PL / PL接口所解释的那样。这个例子说明了DMA的重要性,我将在下一个博客中对实验结果进行解释。
原文链接:
http://forums.xilinx.com/t5/Xcell-Daily-Blog/The-Zynq-PS-PL-Part-Seven-A...
© Copyright 2014 Xilinx Inc
如需转载,请注明出处